In simple terms, machine learning is how we make computers learn from data using various algorithms without explicitly programming it so that it can provide the required outcome – like classifying an email as spam or not spam or predicting a real estate price based on historical values and other environmental factors.
Machine learning types are typically classified into three broad categories
- Supervised learning – In this methodology we provide labeled data (input and desired output) and train the system to learn from it and predict outcomes. A classic example of supervised learning is your Facebook application automatically recognizing your friend’s photo based on your earlier tags or your email application recognizing spam automatically.
- Unsupervised learning – In this methodology, we don’t provide labeled data and leave it to algorithms to find hidden structure in unlabeled data. For instance, clustering similar news in one bucket or market segmentation of users are examples of unsupervised learning.
- Reinforcement learning – Reinforcement learning is about systems learning by interacting with the environment rather than being taught. For instance, a computer playing chess knows what it means to win or lose, but how to move forward in the game to win is learned over a period of time through interactions with the user.
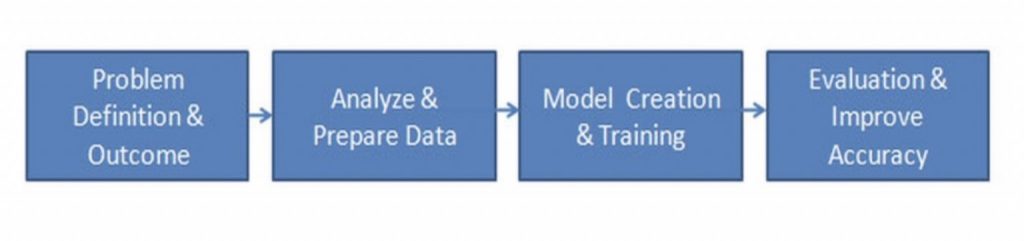
Machine learning process typically consists of 4 phases as shown in the figure below – understanding the problem definition and the expected business outcome, data cleansing, and analysis, model creation, training and evaluation. This is an iterative process where models are continuously refined to improve its accuracy.
From an AI business perspective, machine learning models are developed based on different industry vertical use cases. Domain specific models are key for a succesful ML implementation. Some can be common across the stack like anomaly detection and some use case specific, like condition based maintenance and predictive maintenance for a manufacturing related use case.