Introduction
The word serverless took the world by storm. Let’s talk a bit about this concept called serverless. We all know serverless means running a piece of code on cloud without worrying about the underlying infrastructure – also called as ‘function as a service’. This is what we call a programming model of serverless. There is another perspective or dimension to serverless and that is called managed service or managed infrastructure. The Google cloud extends the definition of serverless as being any service of which its underlying infrastructure is managed by the cloud provider to facilitate dynamic scaling and pay-per-use model. The is the operations model of serverless. It can be perceived as services giving you a serverless experience. Some of the examples are Cloud Storage, BigQuery, Cloud SQL or a PaaS platform like App Engine. A developer simply uses and configures the service and not worry about how the underlying infrastructure operates on the service to keep it resilient and available.
Google Cloud introduced another such serverless platform called Cloud Run that provides a serverless experience in the world of containers. The containers can be run as HTTP workloads and they are dynamically scaled by Cloud Run without the need of writing any scaling routines. The developer simply writes the business logic and push it as a container and let the platform do the rest like deploying, running and scaling the workload. The Cloud Run platform handles all of the low level routines like setting up load balancers, domain mapping, autoscaling, TLS handshaking, identity & access control, logging and monitoring.
Cloud Run for Anthos (CRA) is a Google Cloud managed service that provides serverless experience on Google Kubernetes Engine (GKE). It allows you to configure, build, deploy and run serverless workloads on GKE and on-prem Kubernetes cluster. The said service is backed by Knative platform that offers features like scale-to-zero, autoscaling and eventing framework. CRA is a layer built on top of Knative framework with the focus on increasing productivity by improving developer experience and solving issues related to deployment, routing, scaling to name a few, in Kubernetes.
Knative is an open source framework that provides serverless experience for your containers or workloads in Kubernetes. It is a layer or an abstraction over Kubernetes hiding away complexities of networking and scaling and making it easy for developers to deploy workloads. As per the official website – it solves the boring but difficult parts of deploying and managing cloud native services for you.
Deployment Model
The CRA deployment model is an extension of Kubernetes and consists of Custom Resource Definition (CRD) resources in the form of Service, Configuration, Revision and Route. Let’s look at definition of each of these in the context of CRA.
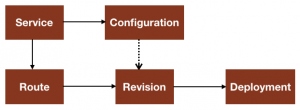
Service
In CRA, a Service represents an application workload which is exposed via an HTTP URL. The application container must be a Web application serving on a specific port. The CRA Service, by default, serves the application on port 8080 unless specified with a specific port. The service YAML is more like a stripped version of Kubernetes deployment resource.
The below is the sample CRA service YAML which looks a lot like Kubernetes resource YAML:
apiVersion : serving.knative.dev/v1
kind : Service
metadata :
name : hello
spec :
template :
metadata :
name : hello-v1
spec :
containers :
- image : gcr.io/cloudrun/hello
When you look at the above code, you will see that it resembles a combination of Kubernetes Deployment and Service resource. But it is different from Kubernetes. It is Knative in action. The value of apiVersion tells us that it is a Knative Serving Service with the kind as Service. The Service name is hello and the revision name is hello-v1. If you do not put the revision name, then it will be autogenerated when deployed. When you deploy the above CRA Service, it also creates Configuration, Revision and Route.
Configuration
The Configuration reflects the current desired state of the deployment. The Configuration resource YAML looks almost like the Service but the Service act as a container or orchestrator that manages the underlying Configuration and Routes. The Configuration simply serves as a template of your latest or the most recent Revision. The controller, based on the desired state, will create the Kubernetes deployment (also called as Revision) behind the scenes. When you deploy a Service, it creates a Configuration resource. Both Service and Configuration can be used to create Revisions.
Revision
Revisions are snapshots of Configuration. Every change to the Service or Configuration YAML under the template section will create a new revision or deployment. The Revision represents a particular version of deployment that cannot be changed. A Revision is associated with a Kubernetes deployment and therefore your application can be rolled back to any previous version or do things like splitting traffic between multiple revisions (Canary) or gradually rolling out a revision (Blue-Green). Revisions can be tagged if you want it be exposed with a different URL than the one generated.
Route
The Route represents the URL or the endpoint to invoke the CRA Service. It’s an incoming HTTP request directed to a specific Revision. The route is automatically created when you create a CRA Service or Configuration. If you happen to redeploy your Service, the route will automatically point to the new Revision. When you delete the Service, the Route is automatically removed. The Route can also be used to specify the traffic behaviour for your revisions or configurations. You could specify what percentage of traffic to be routed to a particular revision or configuration.
Architecture components
When you setup a GKE cluster with Cloud Run for Anthos, it will create two significant namespaces viz. knative-serving and knative-eventing. The knative-serving namespace serves the components that aids in dynamic scaling of your containers also scale down to zero based on the request load. The knative-eventing serves the Eventing framework where CRA service is glued with other external sources or systems to handle and respond to events typically by way of autoscaling. For example, you may have a pipeline formed where data is pushed to Cloud Storage bucket triggering an event causing the CRA service to handle and process the same. The Eventing framework calls for a separate discussion, so we will park it aside for now and focus on core components as part of knative-serving namespace.
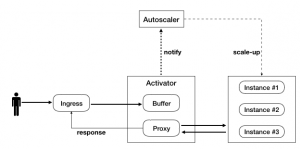
Activator in Action
The knative-serving namespace serves the following components:
Autoscaler
The Autoscaler makes scaling descision based on the no. of requests and accordingly performs the scaling of instances. It checks for the request load and accordingly determines the number of instances to scale. The Autoscaler component has to make a balanced decision between the number of requests and the pods or instances to scale. It plays a role of control plane component more like a control loop to ensure that it catches up with the ongoing demand load. It will scale down to zero if there are no requests in the pipeline. Scaling down to zero is ideal but it can cause problem of cold start. When there are no instances, the first instance could take long time to start and may throw unexpected error to the client application. In such a situation, Activator component comes in handy – which we will discuss next.
Activator
When there are no active application instances or pods i.e. the instances are scaled down to zero, then the client requests are directed to an Activator component. It is a component that mediates when there are no application instances to serve the requests. In such a situation, the Activator will put the request into a buffer and notify Autoscaler to start scaling the instances. Depending on the number of requests buffered, the Autoscaler makes a scaling decision and starts scaling the instances. Once there are enough instances to serve the requests, the Activator will remove itself from the data path and the ingress will directly route the requests to application instances. The Activator also plays a role when there is a sudden spike in the requests and there are not enough instances to handle the spike or load. It will ensure that Autoscaler catches up with the load before the requests are directly routed to the serving instances.
Controller
The Controller component is based on Kubernetes control loop architecture. It constantly watches the deployment resources for any state changes and updates the cluster with the desired state. It embodies a collection of processes that manages mainline deployment resources viz. Service, Configuration, Revision and Route – fulfilling or applying its desired state. It also manages low-level tasks that addresses how the networking works and also performs memory management through garbage collection.
Webhook
This component is modelled around Kubernetes based admission webhooks. The webhook works more like an interceptor that acts on CRA resource like Service, Configuration and Routes, before and after it is admitted or persisted. Some of the things the webhook handles are:
- Override the configuration details like timeout parameter, or concurrency limits
- Modifying or updating routing paths
- Validating the configuration details
- Embedding digest to the partial image or image with no specific tags
You will also find a gke-system namespace that serves the ingress components for your CRA service. The CRA platform uses Istio to provide Ingress gateway for your service. It uses Istio ingress gateway to allow traffic originating from outside the cluster. It makes use of cluster local gateway to allow traffic coming from within the cluster. When you deploy a CRA service, it creates a Istio based VirtualService component for that service which will provide necessary paths or routes to the service and the host using the specified gateways.
The next set of articles, I will demonstrate some of the practical use cases of Cloud Run for Anthos. Cheers!